-
Hacking Wordle through automation and cryptanalysis
Recently, a game called Wordle has exploded in popularity with its simple five-letter guessing game. I’ve been playing it for a few weeks but have also been musing over how to automate this all using my knowledge of classical cryptography.
So let’s dive in!
Patterns in the English language
While English is a very complicated language, it is also rather predictable and it is because of this we can play around with statistics. Letter frequency is often spoken about in cryptanalysis and is often a basis for solving cryptographic puzzles I release periodically.
With Wordle, we’re limited to five-letter words, so what I wanted to do is figure out what are the most common letters per position. The use of letter frequency is helpful, but because we’re dealing with restrictions, the base statistics are merely a guide and not a rule.
Using a list of five-letter words, I generated some statistics and came up with some answers for each position. In order, the first position had the most common letter of “s”, the second “a”, the third “a”, the fourth “e”, and the last being “s”. Now obviously, the word “saaes” does not exist in this word list, but we can use this knowledge to build a score for each word.
By going through the list, we can use the counts of each position to its letter within that position and then come up with a score. For example, the word “sores” in a set of the highest word score and has the values of 724, 911, 475, 1228, and 1764. If we create an average of those numbers, we come up with an answer of 1,020.4.
Using these averages to create a score for each, we can then order a list. That is all right? Well, not exactly, because there’s one other hiccup.
Of the 5,756 words I am working with, 38% of them end in the letter “s”. This is not really all that surprising seeing that four-letter words made plural should not be uncommon. However, I don’t want them to be dominant when I go to automate this later on, so I need to fix this.
While maybe not the best way to do this, I sorted the list in to two halves. The first half were words with all unique letters and the second not. In both halves, the order was kept from earlier, so once we finished the first half starting from the highest score to lowest, the same would repeat on the second.
At this point I decided I was done and felt that I had the most “efficient” list.
Where to start
Now that we have this list, we need to know what word to start off with. I’ve seen a lot of people suggest words like “audio” and “ports”, but the one I seem to find works best is “cares”.
“Cares” has a word score of 967.4, whereas “audio” gets 288.4 and “ports” has 796.6. The point of the game is to produce an answer in as few steps as possible and while you will knock off a lot of vowels and consonants with those two, you are likely reducing the chances of answering in the fewest attempts.
My choice of word also includes the letter “e”, which is the most common letter used in the English language. On average, you should see that letter appear about 10–13% of the time, with the letter “a” being about 7–9%, and “s” being 6–9%.
You can also order it as “scare” or “races” too if you desire, but I believe that with “s” at the end and putting “r” in the middle, you cover all initial possibilities quite effectively here.
Writing code to deal with this
Wordle’s rules are very straight forward: you have five letters and six attempts. On each attempt, the game will inform you on whether or not each letter is valid based on colour. If the letter in a position is valid, it’ll give it a background colour of green, if invalid then grey, and if invalid but elsewhere in the word, amber.
With this knowledge, I went and created a Python script to churn through a word list and find words based on inputs I give. I am solely responsible for the starting word, but the script itself will use my inputs and produce an answer based on the first hit in a list of words which matches the patterns.
The script works by dynamically generating a regular expression pattern for words that are not valid and then goes through to confirm that the letters that are suggested to be anywhere in the word are then only included. It then spits out the first word from the list created which itself is based off of the scoring method I wrote earlier.
It’s fairly simple and runs from a command line.
Testing it out
One hiccup is that Wordle only allows one guess per day. Now, while I could just erase my browser session data to test this out, there is fortunately a clone which not only allows for the same five-letter words, but can also be used on words of which are much longer — and my script can be used on words of any length provided there is a word list.
This clone allows you to keep playing to your hearts content so it became my test bed.

Feeding letters to the script to find the word

Even if the first guess is completely incorrect, we can do it in three steps
The positional arguments in the script are simple. You supply a wordlist (“words_efficient_er.txt”), the letters you wish to completely discard (“c”, “a”, “r”, “e”, “s”, “o”, and “l”), the letters you want to find anywhere (“d” and “i”, or just “_” for none), and then for each position you either put “_” as a wildcard, the known letter, or you precede letters in that position with a “.”, so if you want to exclude “r”, you can do “.r”, or if you wanted “h” and “y” to be exempted, you just do “.hy”.
Because we have the list ordered in a way that allows us to find the most likely word based on positional letter placement scores, it’s entirely possible to have an answer in just two guesses if your first guess isn’t correct. This has in fact happened with my attempts.

Two attempts and we have our answer
This is of course not fool-proof and I have had it take six attempts.

It came very close to not winning here
The placement of “V” and starting with “L” demonstrates that the scoring isn’t exactly fool-proof because it doesn’t take into account the prevalence of the word in the English language. I’d argue that “loves” is more common than the preceding two, but maybe in the case of a random word choice it does not matter?
But sometimes it seems like it won’t get it and then it suddenly it has an answer.

“Girls”
I guess what may have happened on the last one is that the scores for the other words being higher gave it precedence, but ultimately it came across “girls”. This is why I am only so confident in the efficiency of the list because there might be a way to do this better, but it is beyond my knowledge of statistics.
Closing
You can grab the script from this gist here and any five-letter list from a Google search should suffice should you wish to try this all out.
-
Whatever Twitch is doing with machine learning is absolutely useless
Back in March, I wrote about harassment on Twitch towards individual streamers via its chat function. Then, a few months ago, I followed up with a small piece on them admitting to using machine learning when they filed a lawsuit against known bot users on their service.
Finally, in late November, Twitch announced this machine learning feature and I have this short review: it’s absolutely useless.
After its launch, there were still new bots
Twitch has been dealing with a persistent and never-ending bot problem for a very long time. With a number of Black, persons of colour, LGBTQ+, and women streamers taking a stand and the media taking notice, the company finally relented and admitted that they were not meeting their end of the bargain.
It should be repeated here: the only reason why Twitch has made any response is not because of streamers making an issue of this but because the media took notice of the streamers and asked Twitch about it.
So now we have them admitting to using machine learning to track ban evasion and we also have them providing tools to verify users through their mobile phones, but even with all of that it appears that they haven’t dealt with the elephant in the room: they still have massive numbers of accounts being registered to engage in harassment.
The thing about these hate raids is that the bots used them often have been known to have a pattern. With the case of the “hoss” bots, we saw them follow a rather consistent pattern. These bots ceased to exist a few months before the new feature, so did it stop similar patterns from emerging?
The short answer is: no.
On December 3rd, just a few days after Twitch made a big deal about machine learning, 472 accounts were registered in a small time frame. Each of these accounts started with the same 12 characters resembling a popular streamer and were then followed with four integers with the first one being a 0 and then the last three varying.
The first account was registered at 18:58:10 UTC and the last account was registered at 20:01:06 UTC. However, the first 27 accounts were all registered within 2.5 minutes with the remaining 445 all being registered every few seconds starting from 19:47:28 UTC.
How did Twitch’s machine learning not capture such a pattern of account registrations when this pattern was repeating itself nearly every two seconds?
Why I know
I lead moderation for two events run by one of Twitch’s largest channels. My day job is running a cyber security team, so I have a keen interest in knowing how to contend with the nonsense that streamers (including myself) face and how to mitigate the inadequacies the service has automatically.
Twitch’s API is absolutely garbage to deal with when it comes to automating moderation and they make it spectacularly worse for trying to do anything useful that also flirts with violating their developer terms of service.
So here’s the reality: want to know who followed you or another account? You have to have to have a web service receiving pushed messages. Want to ban or timeout a user account? You have to use their IRC-esque service and issue the same commands a human would. Want to pull the user profile? You have to use their REST API.
These are the official ways to perform these tasks and the rate limiting around them is abysmal. The REST API by default limits you to 800 queries per minute and the IRC one is just over 200. If you wanted to ban every single account from one of the hate raid lists out there, it would take 16-hours to just get through 200,000 of them — there is one list that is almost 1.4 million accounts, which would take almost five days.
There are unofficial ways but you raise the possibility of finding your account access suspended or a legal threat being sent your way. There’s an undocumented API that every Twitch user interfaces with all the time, but if you perform an action with it from outside of a browser, you’re violating those terms.
Nonetheless I’ve endured and come up with ways to do all of these things in a way that is fast, doesn’t violate their terms of service, and can be flexible. It has sucked and Twitch hasn’t been helpful, but a year later and I know more about their developer tools than any non-Twitch employee should.
So when these bots come up, I often notice that there are patterns. These patterns more often than not remain consistent and are predictable. In fact, some of these patterns are predictable enough that I literally can anticipate the accounts existing in the future and be aware of their existence within the minute they’re registered.
When that example from before was made aware to me, I put the pattern into the prediction engine and look at that, hundreds of accounts. I am certain that the number I reported may be inaccurate because it’s possible that some were already suspended, but what the hell is Twitch doing when they see these reports? Do they not themselves look for patterns?
If my report from March is indicative of anything, the answer is pretty obvious!
And you know what? It’s ridiculous because everything I have been doing has been largely automated and is performing things faster than whatever machine learning feature Twitch has put out.
And that is just one example. The hate raid lists that have been floating around have patterns too. When I examined one particular set, I was able to cover approximately 40% of them with just one single definition (of a sample set of 480,000 bots, 192,000 were covered). A simple regular expression was able to do that and it wasn’t even that complicated or computationally expensive.
Yet here we are with some poorly implemented machine learning nonsense that could have been done with much simpler techniques. Making it worse, this whole security theatre they’ve put on isn’t even addressing the other problems the site faces.
Spam bots are still around
Here’s a line many streamers will know: want to become famous?
The BigFollows spam bots themselves are indicative of Twitch’s machine learning really not working the way it should. The bots which spam the URLs inviting people to buy up followers, subscribers, and “actual” viewers are all tied together and can be tracked.
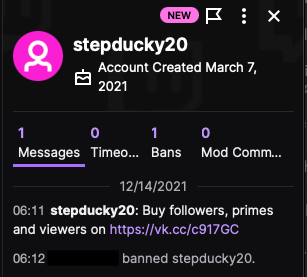
Recent example of a bot spamming a URL which redirects to the BigFollows service.
The service offers customers followers, viewers, and subscribers at varing prices. Need 200 followers? That’s $2.10 US. 30,000? That’s going to be $100.
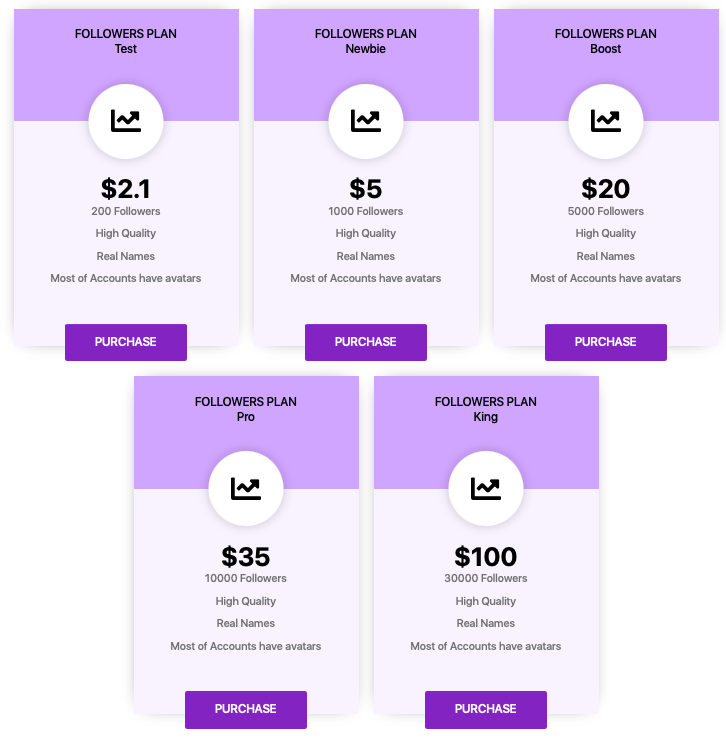
BigFollows showing available plans for gaining new followers. For as little as less than one penny per new follower, you can get 30,000 of them.
The subscriber services they provide is very damning however.
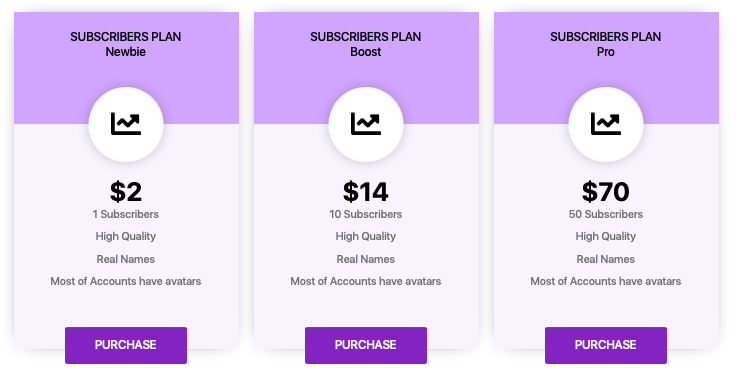
For $2, you can get a $5 subscription given to you. For $70, you can get 50 of them. Each subscription can pay out a customer about $2.50 US each if they’ve reached affiliate status.
For $2, you can get a new Twitch subscriber. For $70, you can get 50. When you take into account that a Twitch subscription itself is typically $5, you can easily come to the same conclusion I am here. The problem is, I have already pointed this out and Twitch is aware of these things, but has done nothing.
Based on my research, BigFollows has about 80,000 accounts available to be used for following customers or spamming its services with a sizeable number available to offer subscriptions.
On October 31st of this year, the service registered 11,107 new accounts between 13:43:46 and 15:22:19 UTC. Every 3/4ths of a second, the service was registering new accounts and this is not just a single blip.
I was able to find the same sort of mass account registrations in 2021 on October 19th, August 26th, and August 14th. For the 14th, we can see 3,700 accounts were all registered in a three hour period, so it has only become worse since.
Personally, I do not care about who’s behind the scenes of this service because I can make a professional guess and say it’s likely affiliated with or linked to organized crime.
However, the fact that this service persists on Twitch and is engaging in what cannot be anything other than fraud leaves me wondering what the hell is going on with Amazon’s audit, risk, and legal teams when it comes to Twitch.
Looking at a buyer
A recent user of BigFollows is Twitch user, yonkukaido. Between their account registration in mid-2018 and until just before last month (November 2021), the account had just 489 follows with just one in 2020 and most being in 2018.
However, with zero activity until November, the account gained over 77,000 new follows starting on the 14th. This is of course for an account with what appears to be zero activity leading up to that point and with a Twitter account in their bio that was registered just this month (December 2021) and has no real activity.
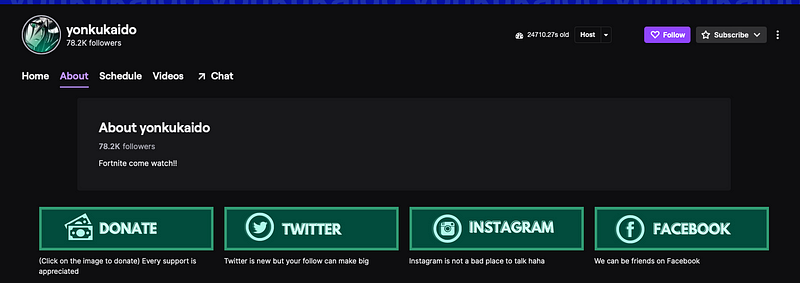
Profile of Twitch user, yonkukaido showing 78,200+ followers with links to the person’s Twitter, Instagram, and Facebook.
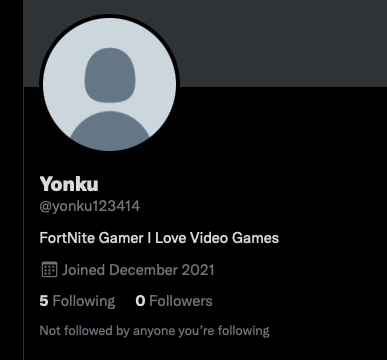
Twitter account, yoku123414 which is linked from from the previous Twitch example.
Their Instagram and Facebook accounts appear to indicate a man possibly living somewhere in the Middle East. The Instagram profile in particular implies that they’re “a gamer”.
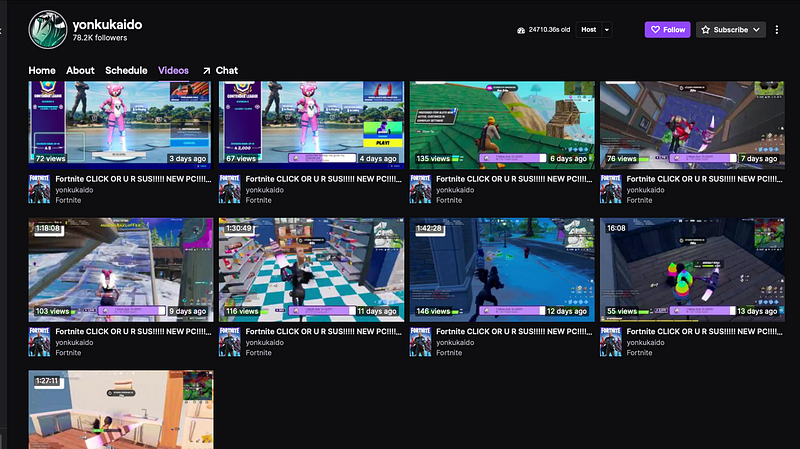
Previous videos by Twitch user, yonkukaido showing streams of Fortnite being played as recent as December 14th, 2021.
When reviewing the video on demand (VOD) streams on the account, the amount of interaction in the saved chat is quite small for someone who has 78,200 followers. Even a streamer with 500 users is going to have a lot more interaction in chat in their hour-long stream than what was shown for this streamer here.
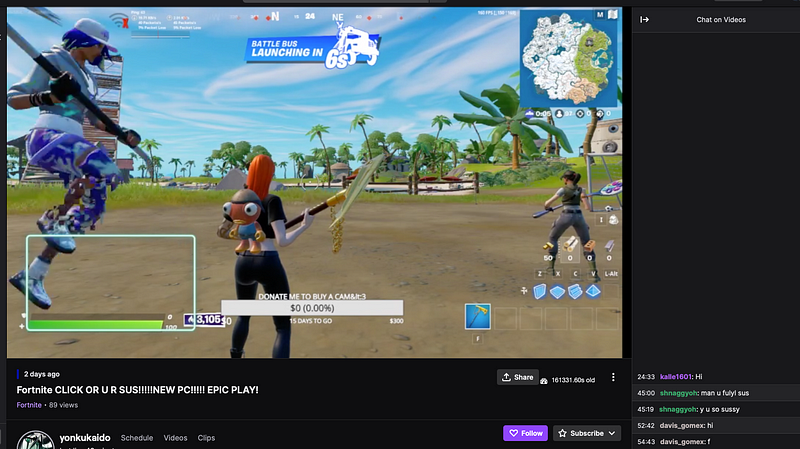
Towards the tail-end of this streamer’s VOD, it shows a grand total of five chat messages in just one and a half hours. With 78,200 legitimate followers, this would be significantly more active.
In reviewing some of these videos, there is little to suggest that they’re even talking on stream. However, evidence shows that they’re streaming from a desktop computer as their are using a Streamlabs progress bar on the bottom, something not possible when using console-based streaming.
Overall, the content they’re streaming and how they interact with their stream plus the lack of progress on their on-screen donation bar should be enough to suggest that their sudden explosion in popularity is falsified.
What is the problem?
Twitch has requirements for becoming an affiliate and also a partner.
To become an affiliate, you require a minimum of 500 minutes of stream time, 7 unique broadcasts, at least 3 average viewers per broadcast, and a minimum of 50 followers all across a block of 30 days.
With partner, it’s 25 hours, 12 different broadcasts, and at least 75 average viewers per stream.
In the case of the Twitch streamer example, they have already achieved affiliate status as their profile permits subscriptions, meaning that they can earn money from streaming on the service. When reviewing the view counts for their streams, it’s apparent that they’re also likely buying up viewers and may have achieved enough to meet partner.
The wildcard in all of this is the subscriber count as unless the streamer divulges that information, it remains unknown. However, we can at least confirm that they’re just an affiliate as Twitch provides a purple checkmark in a user profile for anyone who achieves this status.
The consequences of this manipulation on this user’s part are the same as I wrote back in March: it puts the whole affiliate and partner programs Twitch provides into question.
Twitch’s inaction on this despite knowing about it seems to suggest that it is going to continue regardless of their ineffective machine learning components they keep promoting.
The approach is misplaced and incorrect
Here’s a question: how many Twitch users are going to know what machine learning is?
If you’re me, then yeah, you understand it and you also groan whenever you hear it. But if you’re just someone who plays video games and doesn’t have any knowledge of computing programming, you’re going to see the term “machine learning” and see it as a buzzword.
And that is just it: I don’t see a reason for why Twitch is going on about this because it’s simply all show. The extended moderation tools they’ve put out that allows you to “watch” and “restrict” suspicious users relies on the moderators themselves to engage with them. Twitch barely explains what they do and when I have used them personally, I don’t see their effectiveness especially when dealing with ban evasion.
Twitch needs to investigate further these spam bots, they need to actually do research on these hate raids, and they also need to make meaningful tools that do the basics first.
Give users the ability to ban people from their chats by allowing wildcards (similar to IRC) and make it clear that whatever moderation or reporting decisions are made are given a follow up and an outline of what has actually happened.
Email excerpt showing a report has been sent to Twitch.
To close out, I went and checked my inbox to see how many times I’ve reported accounts to Twitch and in 2021 alone I reported 152 users and of those 38 received a follow up. This meant that for every four reports I would make, only one would get actioned on and unfortunately Twitch doesn’t make it clear who you reported or who was actioned upon.
This excerpt contains as much information as the whole email itself on what has actually occurred.
I report not because I expect Twitch to do anything but because I wanted to know how often they actually bothered to enforce their terms of service.
Twitch hasn’t done better.
-
Thoughts on punditry during Facebook’s October 2021 outage
God. I hated and enjoyed the stories and wrong opinions which came out on October 4th, 2021, as Facebook and all of its associated services effectively “disappeared” from the Internet for a half-day. Some of them were the type I wanted to believe, some of them were outlandish, and some of them came from folks who probably need to learn a bit about Hanlon’s razor.
This is probably my favourite tweet. It would have been pretty funny to have had the new Matrix movie release on the same day as this incident.
A good primer on what actually happened can be read from CloudFlare and Facebook for their part posted a fairly reasonable explanation as well. I won’t dive into these two any further, but I do want to talk about some of the silliness I saw on Twitter, the only working social media outlet that day.
Facebook could not get into their offices as a result of this
Turn-key LDAP systems such as Active Directory are so yesterday.
I want to believe this so bad because it would read as both funny and so many movie scenarios coming to life, but it isn’t true.
Runner up for my favourite tweet.
My last visit to Facebook’s Menlo Park campus (on “1 Hacker Way” no less) was a surreal experience because it was very much high-tech in terms of how you signed in, how you got around, and how people worked. Much has likely changed since my mid-2016 speaking engagement there, but advances in access control and so forth have not fundamentally changed.
The company is in fact married to their ID badges. Everything from ordering food, getting office and computer supplies, booking and using conference rooms, and just opening doors is tied to the ID badge. However, at no point did it ever appear that there were no workarounds.
Many came out to say that they had spoken with people who work at Facebook. It is likely that this messed with many of its internal systems, but the disruption was probably not as severe as many made it out to be.
It is possible this whole incident disrupted physical access, but I don’t think that it lasted anywhere as long as some may suggest. Internal tools were disrupted and it likely affected access control systems, but I imagine they still had physical keys somewhere.
I know that the Bay Area is rife for flaunting local municipal and state code, but nobody running physical security for a company as high-profile as Facebook is going to overlook the need to override the digital controls. It is likely that nobody could fix this remotely (as in working from home) as Facebook was “gone”, but it would be spectacularly unlikely to have completely locked everyone out.
Many large corporations use IoT devices to operate their conference rooms. They’re not new at all and often are synchronized with the internal lighting, telephony, video conferencing, and electronic displays.
The company also doesn’t have a data centre in its Menlo Park offices. In fact, the closest data centre to them is 800 KM north in Bend, Oregon. Additionally, they have multiple data centres, with at least a dozen in the United States, a few in Europe, and one in Asia — this is via unofficial sources I will add. If someone had to do this on site, it was likely at one of these locations.
Lots of data was stolen and a panic button was hit
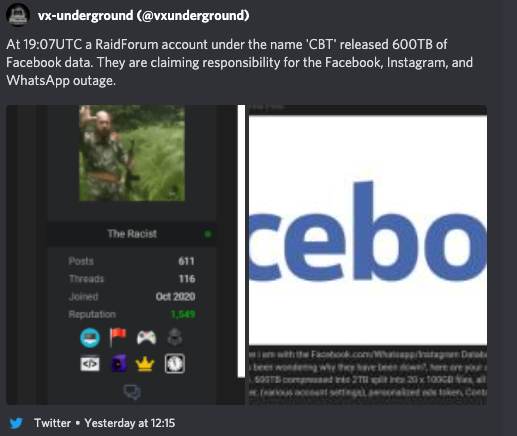
A now deleted tweet from Twitter user, vx-underground: “At 19:07UTC a RaidForum account under the name ‘CBT’ released 600TB of Facebook data. They are claiming responsibility for the Facebook, Instagram, and WhatsApp outage.”
600 TB is a lot. How much is 600 TB?
From a practical standpoint, let’s look at a 4K movie on Blu-Ray. In this scenario, a movie could be anywhere between 50 and 100 GB in size. On my 940 Mbps Internet connection, it can transfer about 117 MB every second at its maximum capacity. Assuming the maximum size of 100 GB (or 102,400 MB) was being used for the movie, it would take me under 15 minutes to download it via the Internet.
The tweet about data being made available on a “popular hacking-related forum” made its rounds and spread like wildfire without taking into account the absurdity of the claim.
600 TB is 614,400 GB which is 629,145,600 MB. That’s 6,144 of those aforementioned Blu-Ray 4K movies. That means that it would take my connection approximately two months to transfer the data, assuming I could do it at peak and without disruption.
Physically, to store all of that 600 TB on Blu-Ray discs alone would result in the discs alone being just over 7 metres tall. For reference, I am about 1.7 metres in height and as a result those discs would dwarf me.
If we were to use hard drives, the largest capacity on the market today runs at 18 TB, meaning you’d just need 33 of them if redundancy is not important.
At a minimum, you’re looking at about $600 (Canadian dollars) for just one drive, so that comes to just under $11,000 before taxes and recycling fees — maybe you can get a bulk discount. You’d also need somewhere to put those hard drives too, so it will then cost you at least another $10,000 more since you cannot stuff that many into your computer.
And I guess physically speaking, the hard drives would be shorter than the Blu-Ray discs themselves as they’d just be a metre tall all combined.
Since I am not fond of mechanical hard drives, solid state drives run you $1,100 for 8 TB each. We’d need 75 of those (again without redundancy), running you $82,500. Height wise, it wouldn’t be much different than the previous storage medium, but it would be considerably less noisy. You’d still have to add the cost of housing that many drives.
Mirror it on the cloud then? Using Amazon Glacier, you can store data there at $0.004 (US dollars) per GB per month, or $2,460 for the whole 600 TB, assuming you have managed to get it into there. However, making use of the data would then cost you a lot more, as retrieval of the data will likely cost you $0.01 per GB. If you wanted to grab it all after storing it, it could set you back about $6,150, setting aside the costs of storing it locally to begin with.
So no. Someone doesn’t have 600 TB of data for sale — at least not in this situation. If anything, it’s likely that they could have been packaging scraped data and some data floating about that connects Facebook users to their telephone numbers, but even then it doesn’t get close to a single terabyte and I know this first-hand.
Why did I initially use Blu-Ray discs to demonstrate this then? Aside from their storage density, Facebook was reported to have used them to store data long-term as early as 2014. Whether or not it is still the case is uncertain.
To add to this: moving 600 TB out of Facebook’s data centre should hopefully not go without notice despite the amount of data they move typically.
There was a thought popped into my head where someone could walk out with a whole bunch of discs, but I don’t think that can and will happen as 10,000 discs would weigh about 160 KG and would be almost 12 metres if stacked high.
You may as well steal a storage array, which would be needed for all of those hard drives I mentioned.
It was all a “security reset”
I am obscuring this tweet because the person in question has faced enough harassment in their life, but nonetheless, their tweet was so incredibly misinformed that it irritated the hell out of me.
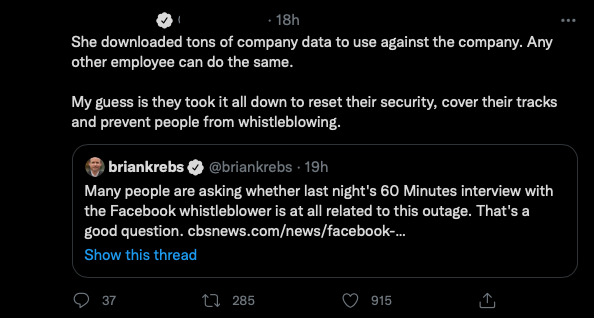
Quoting a tweet by Brian Krebs: “She downloaded tons of company data to use against the company. Any other employee can do the same. My guess is they took it all down to reset their security, cover their tracks and prevent people from whistleblowing.”
The day before, former Facebook Product Manager, Frances Haugen revealed allegations (of which I do believe) of the company amplifying content that would be considered hateful, likely fuelling the fascist fervour surrounding the 2020 American presidential election and the subsequent January 6th failed coup (and let’s not mince words here, it was an attempt) on the U.S. Capitol building.
This is of course incredibly damning for the company as they had continuously denied this in press releases and through its own founder and CEO, Mark Zuckerberg in front of congressional hearings.
Why this person’s tweet is so incorrect is quite simple: why would you go about “resetting security” the day after? Nuking any way for people to get to any of the company’s services does not ease “resetting” in whatever form this persons believes and is also incredibly expensive.
Facebook is a for-profit, service-oriented business and consequently downtime of any significance is going to cause them to incur financial penalties from their customers let alone their own revenue streams. Their business is in providing a functional service and data from its users. Being out of commission for a half-day means a loss of that data and in turn a loss in profit.
So what if Facebook actually did do this? Well, the legal hot water they may presently face over these believable allegations would become significantly worse if it came to light that this downtime was all a ruse to get their “ducks in order” in the event that they were requested to provide information to law enforcement. Digital forensics would be all over this because there would have to be communications between higher ups and everyone required to pull off a such a ridiculous stunt.
To add to this, it likely would result in another whistleblower situation. I would imagine that this would all bubble to the surface much faster than the time between Haugen’s departure from the company in May and her appearance on CBS’s 60 Minutes just this past Sunday. Someone in the chain who would have the ability to do all this would likely make noise.
Assuming it were somehow successful and were to come to light, it would likely be a bigger corporate story than the Enron scandal, which coincidentally occurred almost twenty years ago prior.
This would not be a financial crime of course (maybe a Sarbanes-Oxley violation due to a messing with controls perhaps — I am not a lawyer), but seeing that it would be an blatant attempt to erase evidence and there are already enough within Washington D.C. who have a bone to pick with the company, I don’t think they’d ride this one out with the same ease Microsoft did when they faced anti-trust suits the same year as Enron broke.

Now that we are at the end: it was aliens. That, or sun spots.
So no. I don’t see it at all possible as hitting a “reset switch” here as the ramifications would be enormous. In truth and all likelihood, someone coincidentally committed code that messed up production, which then cascaded to catastrophic collapse of vital systems. It fits in with Hanlon’s razor as mentioned at the start of this piece and there is just no evidence to suggest otherwise.
The one theory I did have is maybe a “white knight” situation, where someone opted to fall on their own sword for some misguided reason, but even then I don’t buy that possibility.
-
Twitch has made a good step with preventing harassment but it has pitfalls — also what the hell is…
I have written extensively about the problems Twitch has with harassment via user interactions, so it should come as no surprise that I have been keeping myself informed of the the activities that eventually lead to A Day Off Twitch, where many streamers protested against the company’s milquetoast response to the problem by not streaming. While I have many opinions about how everything was co-opted and mutated from what the #TwitchDoBetter movement, I am of the opinion that the media attention it receive was likely beneficial.
Earlier this week, Twitch finally announced seemingly effective tools to contend with harassment. Streamers can now enforce a requirement for users to have either or both e-mail and phone-based verification (via SMS) before they are permitted to participate in chat. Being that many users legitimately may not have done either prior to this new feature, streamers can permit users who have accounts with a specific age to avoid either, they can elevate them to VIP or moderator status, or require them to subscribe (as in pay the streamer) to participate.
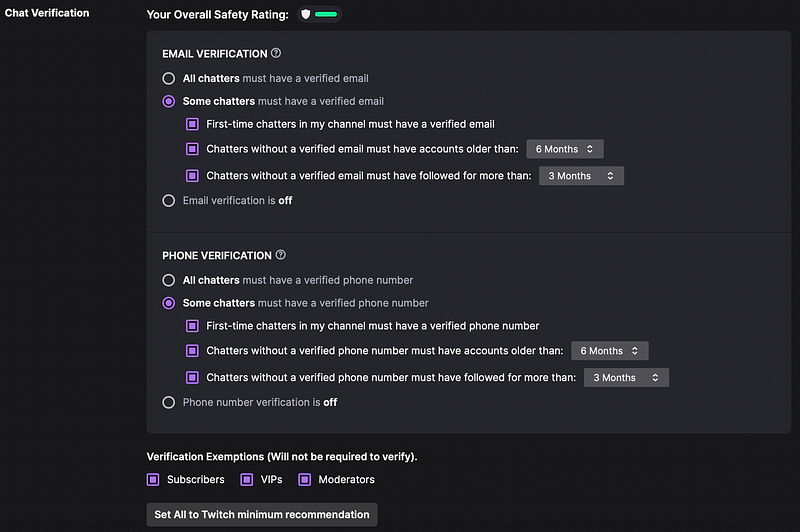
Moderation configuration settings from a Twitch dashboard. Options show e-mail verification and phone verification with settings for first time chatters, with additional features for chatters without verification being granted permission to participate with a minimum account age.
The one thing many streamers had called for that is not mentioned at all in the above screenshot is this one pertinent feature from the announcement:
We know there are many reasons someone may need to manage more than one account, so you can verify up to five accounts per phone number. That said, to help prevent ban evasion, if one phone-verified account is suspended site-wide, all accounts tied to that number will also be suspended site-wide. Users won’t be able to verify additional accounts using a phone number that is already tied to an actively suspended account.
At the channel-level, if one phone-verified or email-verified account is banned by a channel, all other accounts tied to that phone number or email will also be banned from chatting in that channel.
This is huge as for the longest time, a harassing user could just register multiple accounts to a single e-mail address without consequence. While it is easy to have multiple e-mail addresses, there is a much larger barrier to having multiple phone numbers capable of receiving SMS.
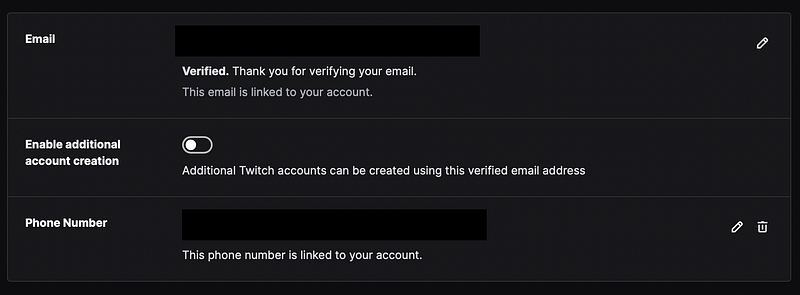
User account settings showing that a phone number and e-mail address are linked.
However, be that it may, it comes with many caveats and one in particular comes to mind: not everyone has access to mobile phone service, and this could lead to an inequity situation for some. Twitch themselves even point this out in the announcement.
If I don’t have a mobile phone, does this mean I can’t participate in chat anymore?
If your account is not phone-verified, this will not prevent you from watching and enjoying a stream — but it does mean there may be some channels you are unable to chat in if they have phone-verified chat enabled. Creators can also choose to make exceptions to phone-verified chat for accounts of a certain age or following time, as well as VIPs, moderators, and subscribers.
This comes down to the creator being benevolent or permissive with how individuals can participate and could just outright exclude anyone who is unable to verify via their mobile phone. The minimum age for a user to have a Twitch account is on paper thirteen years, and while many who are younger often have mobile phone service, there are many who do not. While I personally do not want anyone younger than 18-years old to participate in my stream, I do know that this is not desired by everyone.
The other problem is that this likely has some limitations. Twitch’s goal is to make harassment more expensive and is something I advocated when I wrote about this problem earlier this year, but based on how I am seeing it written about by the company, I do believe that there are workarounds.
My burning question for one workaround is this: how do the e-mail address-based ban evasion avoidance techniques take tags into account? Many e-mail services, including Google’s, support the appending a tag to an e-mail address wherein you append ‘+’ to the end of the first half of your address (also known as the “local part”) with a label following soon after.
Many do not and perhaps should not scan for this sort of thing as the rules for what can and should be in a local part are sort of defined, you cannot be assured that the use of a tag is implicit of anything as it is dependent on the e-mail service to start with. Does Twitch scan for this potential problem? I have my doubts and may consider testing this if someone else hasn’t already.
I also pointed out that there are throwaway e-mail services, and those can be used to verify an account. What is Twitch doing about that? There are lists that are freely available for them to use to detect the use of the, but are they doing this?
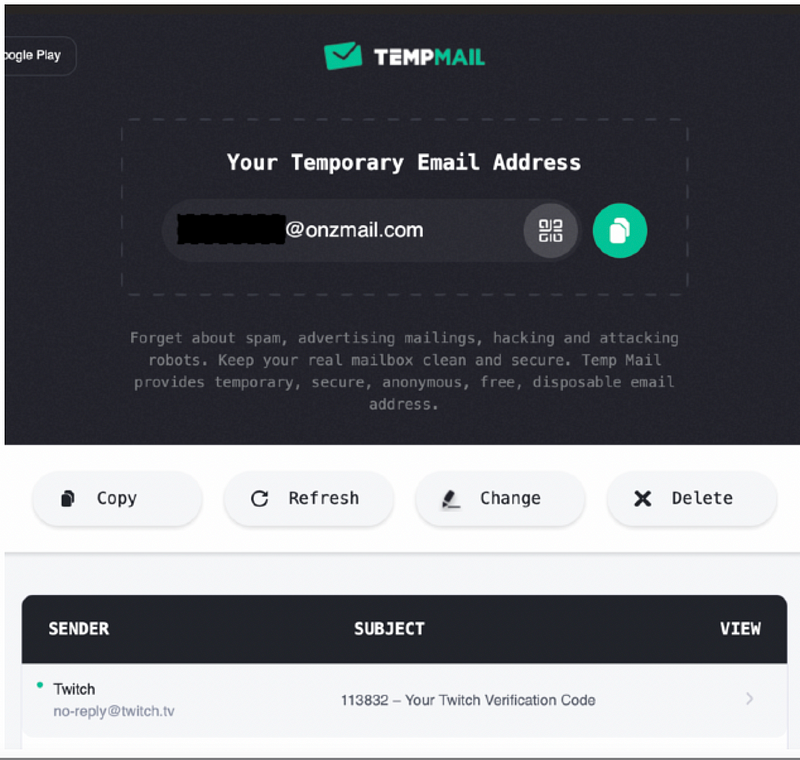
From page 35 of my March 2021 report on Twitch harassment. This shows a throwaway e-mail service granting me a verification code for my new account.
So then we’re led into this scenario: let’s verify by mobile phone? This seems to be straightforward as surely it is hard to evade that way?
It is a valid assumption as while I have had to buy disposable SIM cards for consulting engagements, not everyone is going to have more than one or two mobile phones. However, this assumption is still wrong as there are throwaway SMS services.
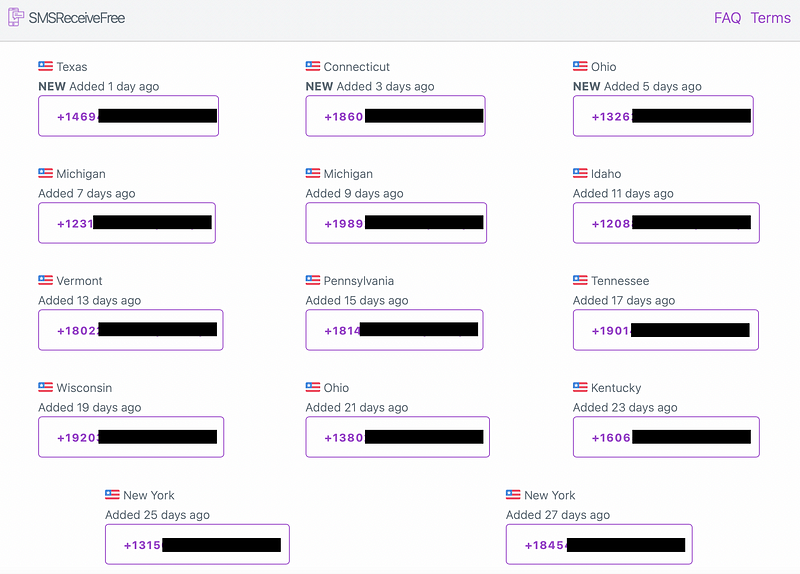
A service showing available mobile phone numbers for web-based reception of SMS messages.
Now, I will admit that these numbers provided by this and similar services are often exhausted extremely quickly. There is also the consideration that there is a finite quantity of available numbers on these services, but it is a matter to give thought to when relying on this scheme.
Overall, I am supportive of this new feature, but the equity issue and the potential evasion techniques remain.
So what about this lawsuit?
On September 10th, which was two and a half weeks before announcing these features, Twitch filed a civil suit in Northern California against two Europeans who are alleged to have created software to engage in harassment on the streaming service.
The timing has always baffled me because it would have made sense to drop this feature and this lawsuit on the same day. Many found that this was Twitch trying to look like they were doing something instead of anything concrete and this further alienated streamers from the company. In my case, I found the filing rather damning towards the company themselves, because they admitted a few things that I find rather embarassing.
However, despite Twitch’s best efforts, the hate raids continue. On information and belief, Defendants created software code to conduct hate raids via automated means. And they continue to develop their software code to avoid Twitch’s efforts at preventing Defendants’ bots from accessing the Twitch Services.
This paragraph (51) was rather interesting because I want to know more about “Twitch’s best efforts”, There have been rumours for many years that there remains a workaround that permits harassers to create en-masse accounts to engage in harassment without any response from the company. I cannot elaborate further on this problem, but honestly it isn’t here where I raise my eyebrow.
To further curb Defendants’ hate-raids, Twitch updated its software to employ additional measures that better detect malicious bot software in chat messages.
Twitch expended significant resources combatting Defendants’ attacks. Twitch spent time and money investigating Defendants, including through use of its fraud detection team. Twitch also engineered technological and other fixes in an attempt to stop Defendants’ harassing and hateful conduct. These updates include but are not limited to implementing stricter identity controls with accounts, machine learning algorithms to detect bot accounts that are used to engage in harmful chat and augmenting the banned word list. Twitch mobilized its communications staff to address the community harm flowing from the hate raids and assured its community that it was taking proactive measures to stop them. Twitch also worked with impacted streamers to educate them on moderation toolkits for their chats and solicited and responded to streamers’ and users’ comments and concerns.
These “stricter identity controls” stand out as we did not see tools for streamers being made available to leverage this until recently, but what really raises my ire is them stating they’re using “machine learning algorithms to detect bot accounts”.
What the hell sort of “machine learning” have they deployed? I even criticised this on Twitter.
Of the 174 “hoss” follow bots that have been known to exist at the time of this writing, with the majority appearing since mid-August, they all share a common pattern which can be easily snuffed out with just two very basic regular expressions:
^hoss0{0,2}312_{0,1}.*
^.*_{0,1}hoss0{0,2}312$Just what the fuck? How is this so complicated? You can do this with just one regular expression, but it isn’t that much more costly to do it with two and it is much easier to maintain.
My only theory about this “machine learning” nonsense can be summed up in this Discord conversation I had on the day I read the filing:

My parodic interpretation of a meeting at Twitch HQ about the chat moderation problem: “this is my theory about a meeting [on] moderation […] recently: a: “okay. so these fucks are asking us to make moderation better. what do we do?” b: “well, i have been doing machine learning for funsies on udemy and i think it would work well?” a: “that is hot shit. we can’t do this with blockchain?” b: “working on that later. nft stuff first ya know” c: “hey. why don’t we revisit my idea of just allowing bans based on how they work on irc?” a & b: “no. fuck you” a: “besides, we don’t get to do machine learning for anything beyond marketing””
I have rather poor opinions about Twitch’s approach as evident above.
The solution of using machine learning at least to me appears to be something “hot and sexy” when in reality we need something conventional. I have done a lot of work around using entropy to detect malicious activity in my line of work, but it was only done after making other attack methods more expensive, which should be done first as it is often easier to do.
At least we finally got these new verification tools, but honestly, Twitch has a lot remaining to do and I am not holding my breath.
-
What is in your BC Vaccine Passport?
As you may be aware, those in British Columbia are joining other jurisdictions in issuing “vaccine passports”, which is basically a verification system to show your vaccination status. This is to combat the spread of COVID-19, and is intended to ensure that those who are unvaccinated do not pose a threat to those who are.
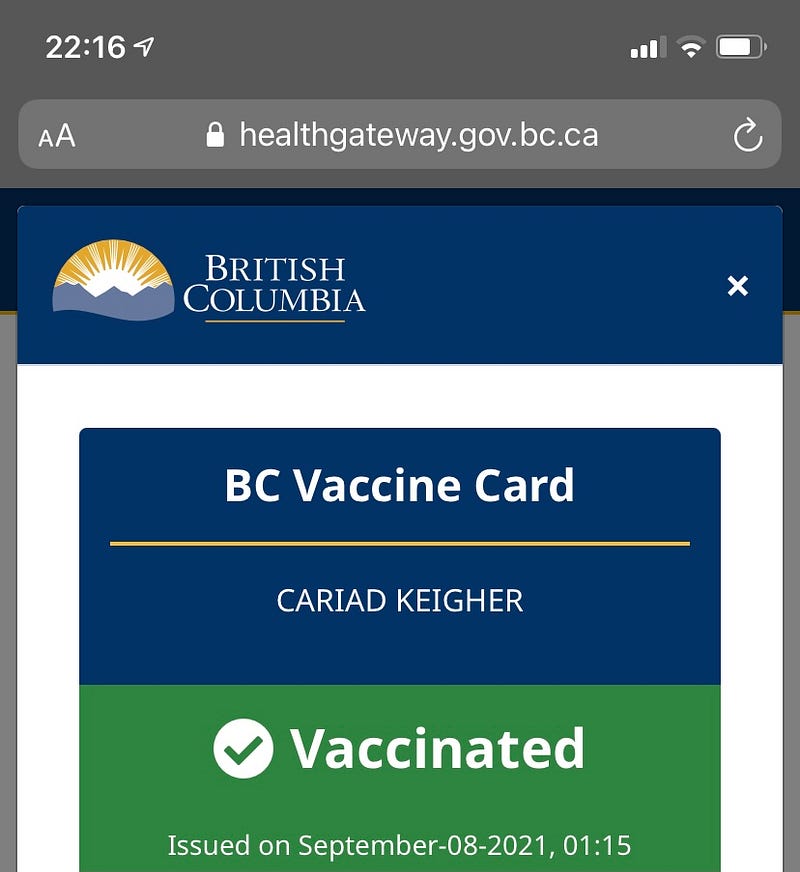
BC Government Health Gateway showing my “BC Vaccine Card”
If you’re reading this and are about to go tweet at me or write some diatribe to my e-mail address about vaccines being tyranny, I have a simple response: fuck off.
I have professional concerns about the passport myself, but they’re based on equity for those who are unable procure a personal health card for whatever reason. If your concerns align with the thousands who opted to hinder access to local hospitals, you’re a fucking dickhead and I do not care about your baseless and factless opinions.
Anyway, historically, these are not new at all as during my own parents’ lifetimes before my being born, they existed for Canadians who needed to travel abroad. However, we’re now in the age where our mobile phones are capable of providing an aspect of verification of vaccination status.
Website for SMART Health Cards
It was feared initially that every jurisdiction would adopt a system of their own to work with the data, but fortunately it seems that British Columbia has adopted the same system as Québec, which is to use the SMART Health Card system, a standard developed by the W3C Consortium, who are behind the standards for the world wide web.
Much like how the world wide web work with establishing encrypted connections for online banking, the SMART Health Card (“SHC”) uses the same methodology to verify the contents of the presented QR code. The QR code can be shown to anyone with an mobile phone running an application capable of reading it, and then the details on the application can be compared with some photo identification to confirm that the QR code belongs to the person they’re interacting with.
The QR code can be on your phone, a piece of paper, or in one case with someone in Québec, printed on a t-shirt so it could be read metres away.
Anyone can read this QR code and with that it may raise some eyebrows.
So now you’re wondering: what makes it safe? How does someone not get my personal details? These are legitimate and important questions and it can be answered quite easily: the issuing health authority is only supposed to put as much information as needed on the card.

The SMART Health System is clear about what can be on a person’s card.
As it stands, the standard should contain your legal name, date of birth, tests if relevant, vaccinations, and contraindications should you have any. It is spelt out as per the image about that it should not contain your phone number, your address, an identifier such as a personal health or drivers licence number, and other health information. The SHC standard straight up outlines keeping data at a minimum and has a whole section on privacy.
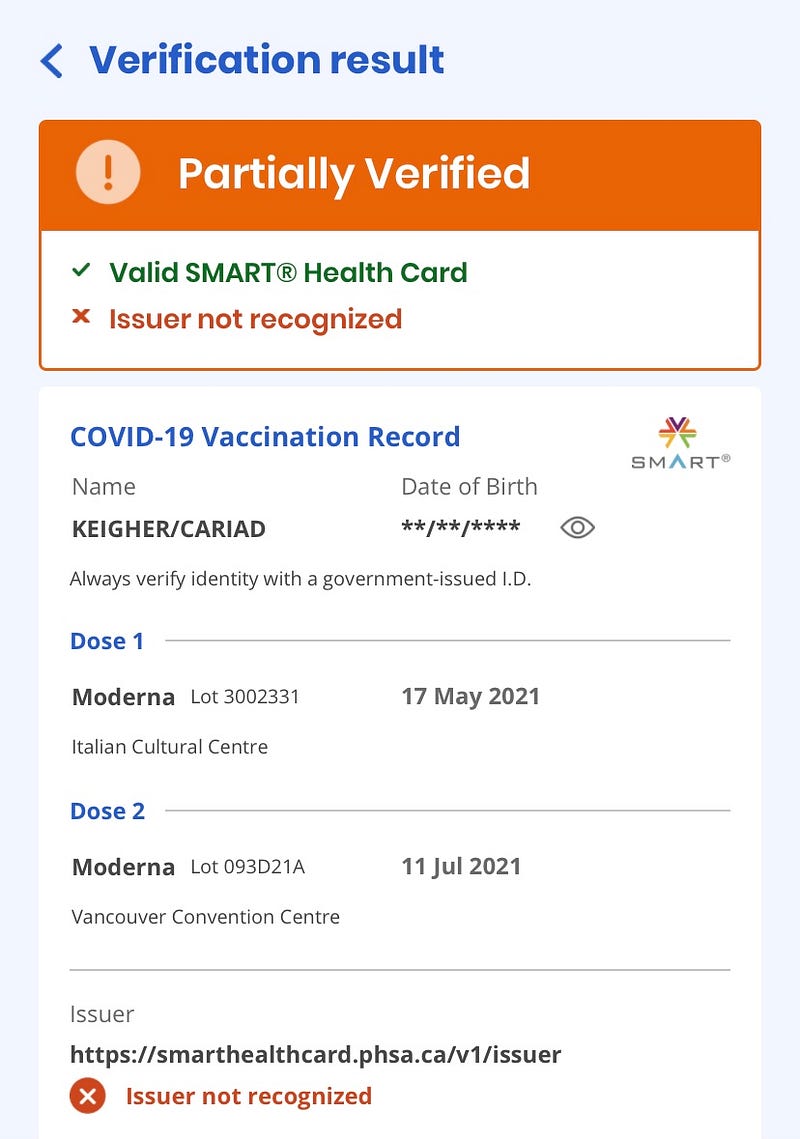
Output from a SHC QR code reader. The “issuer not recognized” remark at the bottom should be of no concern until the programme goes live in a week. I would expect that to go away by then.
So does British Columbia adhere to the recommendations?
I have gone ahead and decoded my passport (using this methodology as a guide) and was able to glean from the data that it has the following:
- The issuer (ISS), which is remarked as the Provincial Health Services Authority (PHSA)
- The creation date (NBF), which is an epoch time stamp of seconds since January 1, 1970 00:00:00 UTC (standard for most computer data)
- The type of card it is, with the data outlining it is for COVID-19, immunization, and is a health card
- The family name of the passport holder
- The first or given name of the passport holder
- Their birth date
- Their immunization records and date of occurrence for each plus the vaccine type, lot number (which box or order the vaccine came in), and where it was given
That is it. There are no health numbers, no address, and surprisingly, no mention of the person’s gender. I have concerns about the name aspect for those who are transgender as it could out them, but that is it.
You can safely show this QR code to someone else if someone requests you of that information. If you’re running a wedding, you can have your guests confirmed that they have been vaccinated. All you need is to have photo identification to verify the contents of the QR code and through the power of mathematics, it is incredibly difficult and likely impossible to forge a QR code that can thwart this system.
Go ahead and print this out, make an iOS shortcut that is super useful, or put it on a t-shirt. It’ll be a piece of identification until we get through this mess we’re still in.
All we are waiting on is for the PHSA to become an recognized issuer and anyone can trust this vaccine passport. A vaccine passport issued in British Columbia will also work in Québec and vice-versa and while it may have issues internationally as I am certain that someone in Florida or Belgium may not know what the PHSA is, they’d still be able to read the data anyway.
Go get your passport if you have gotten your vaccine and if you haven’t gotten your vaccine yet, go get it. If you don’t want to get your vaccine, leave everyone alone and wait out the pandemic so you don’t spread it or worse get sick.
My remaining concern right now is: what do we do about those who cannot get access to the website? Equity is still my problem with all of this, and my concern lies with those who are undocumented or are of no fixed address, just to name a few.
Update: it seems that you can just call in to get a non-digital copy of the passport should you run into some issues related to equity.